【量化金融】利用HIST模型挖掘股票概念进行预测

【量化金融】利用HIST模型挖掘股票概念进行预测
6Young基本介绍
我们都知道,在股票市场中,“板块联动”效应十分的强,也就是说同一类型的股票常常同涨同跌。因此,为股票们预定义一些概念,比如他们参与哪些业务,是否属于某一行业,是否存在上下游供应链关系等等。但是这些预定义的概念不可能完全的描述股票的属性,不属于某一概念的股票也会受到其他概念热点新闻的间接影响。而且每只股票也一定会有自己独特的信息性质,造成市场中的所有股票都有独特的涨跌属性。
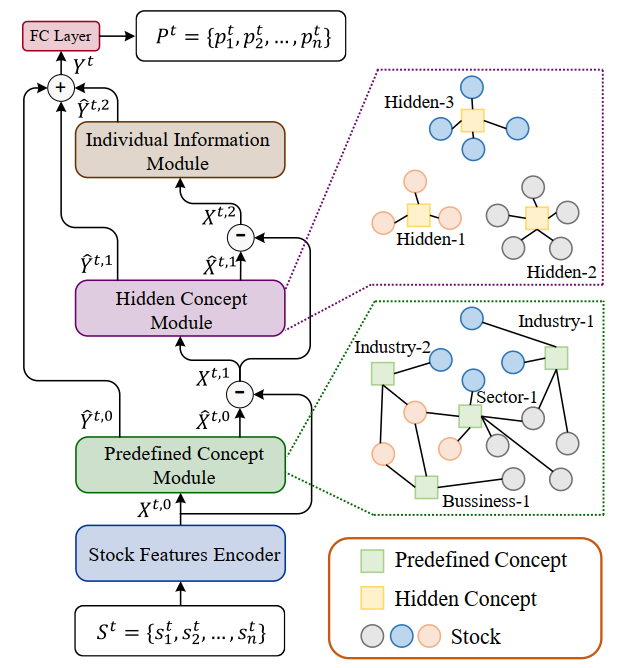
本文准备介绍和复现的HIST模型是Wentao Xu在2022年1月提出的,其优势是在模型提取“共享概念”中所包含的信息时,考虑了概念的不完备性和动态变化性。将股票的特征由以下三个部分来解释:
- 股票所属板块所包含的共有的预定义信息(Predefined Concept)。
- 预定义中不包含的隐含信息(Hidden Concept)。
- 每支股票独有的特质信息。(Individual Concept)。
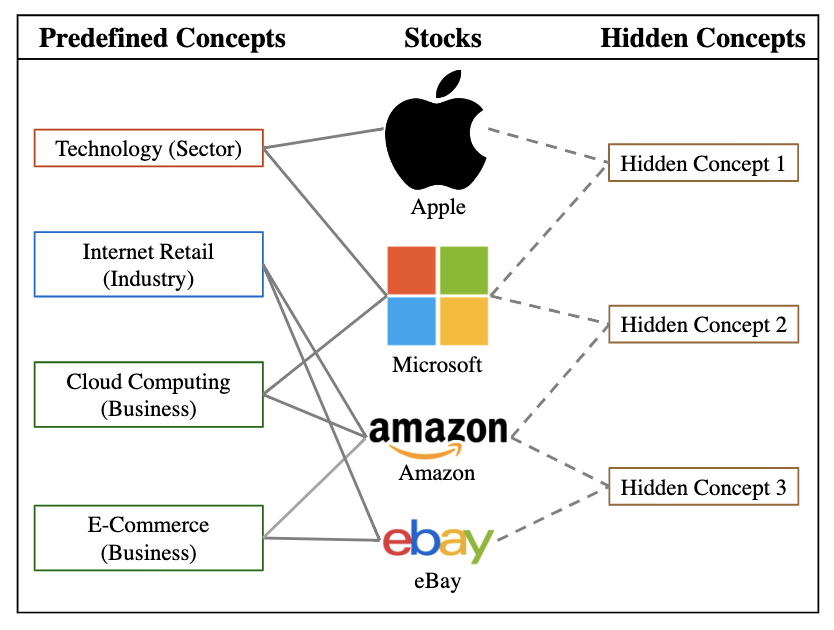
用作者在文中给出的例子,苹果与微软都是科技板块的公司;亚马逊与微软都在做元计算相关的业务,这些都属于预定义概念(Predefined Concept)。而所谓的隐含概念(Hidden Concept)是通过神经网络自适应迭代学习出的一组矩阵。
根据上述的设计与理论,最终形成的网络结构情况如下图所示。
数据准备
为了复现并训练这个模型,我们需要准备很多的数据。
股票池: 沪深300以及中证100成分股的收盘价信息,这是我们用以预测未来价格的基础。
股票预定义概念: 上市公司行业分类、主营业务。
股票特征: 论文作者使用了微软Qlib中计算提供的Alpha360因子,提供了不同维度的股票特征,当然,我们也可以使用聚宽的alpha191或者Worldquant的alpha101作为特征。
时间跨度: 以2007-01-01至2014-12-31的数据为训练集;以2015-01-01至2016-12-31的数据为验证集;以2017-01-01至2020-12-31的数据为测试集。
Stock Features Encoder
使用2层的2GRU网络对股票的原始特侦进行表征提取:
$$
x_i^t=GRU(\textbf s_i^t)
$$
其中,$s_i^t$是股票$i$在时点$t$时的对应的因子序列,$x_i^t$是对应股票经过门控循环单元提取出的表征,由此构成了矩阵$\textbf X^t$是在时点$t$时的表征矩阵。
Predefined Concept Module
概念表征初始化
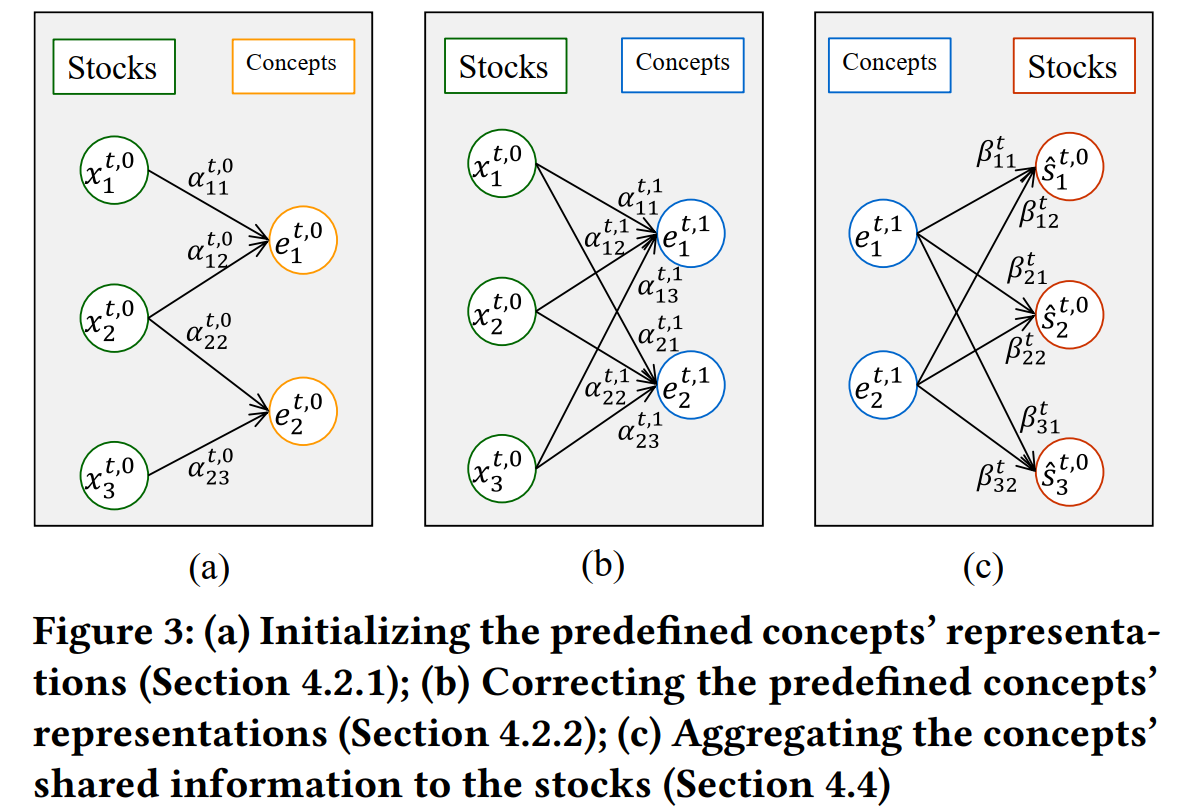
在这一部分中,我们首先构建股票-概念的二分网络$N^t$。然后通过股票市值$c_i^t$计算出的权重$\alpha_{k,i}^t$将每一个概念所对应股票的表征$x_i^t$进行加权求和,以此作为概念$k$的初始化表征$e_k^t$。
$$
\alpha_{k,i}^t = \frac{c_i^t}{\sum_{j\in N_k^t}c_j^t} \
e_k^t=\sum_{j\in N_k^t}\alpha_{k,i}^tx_i^t
$$
概念表征处理
为了解决预定义概念的信息缺失和预定义概念的信息过剩的问题,我们需要计算股票表征与概念表征之间的相似性,如果一个股票与某个概念相似性很高,但在预定义概念中,这个股票与这个概念并没有相连,那就可以视为缺失的关联。反过来,如果股票与某个概念间相关度不高,但在预定义概念中两者相连,则这个关联是没有必要的。
在这里,我们使用余弦距离度量股票与概念之间的相似性,并用Softmax归一化后得到新的股票-概念权重,可以将之传入一个简单的全连接层$(W_e, b_e, LeakyReLU)$后计算得出最终的概念$k$的表征$e_k^t$。
$$
\alpha_{k,i}^t = softmax(Cosine(x_i^t,e_k^t)) \
e_k^t = LeakyReLU(W_e(\sum_{i\in S^t}\alpha_{k,i}^tx_i^t)+b_e)
$$
共有信息剥离
为了给下一个“隐含信息模块”提供有效的输入,我们需要去除概念之间的共有信息。同上一环节的$\alpha_{k,i}^t$一致,我们通过余弦距离与Softmax方法计算出股票$i$与概念$k$在$t$时间,归一化后的相关性。接着,把股票$i$与所有概念$k$的表征加权总和,传入全连接层$(W_s, b_s, LeakyReLU)$,输出作为股票$i$所包含的预定义概念的相关共有信息。
$$
\beta_{k,i}^t = softmax(Cosine(x_i^t,e_k^t)) \
\hat s_i^t = LeakyReLU(W_s(\sum_{k\in K^t}\beta_{k,i}^te_k^t)+b_s)
$$
最后,将$\hat s_i^t$传入两个全连接层,输出$\hat x_i^{t,0},\hat y_i^{t,0}$:
$$
\hat x_i^{t,0} = LeakyReLU(W_b\hat s_i^t+b_b) \
\hat y_i^{t,0} = LeakyReLU(W_f\hat s_i^t+b_f)
$$
计算得到$x_i^{t,1}=x_i^{t,0}-\hat x_i^{t,0}$作为下一个模块的输入;$\hat y_i^{t,0}$就是本模块的最终结果,代表着最终的获得的“预定义信息”。
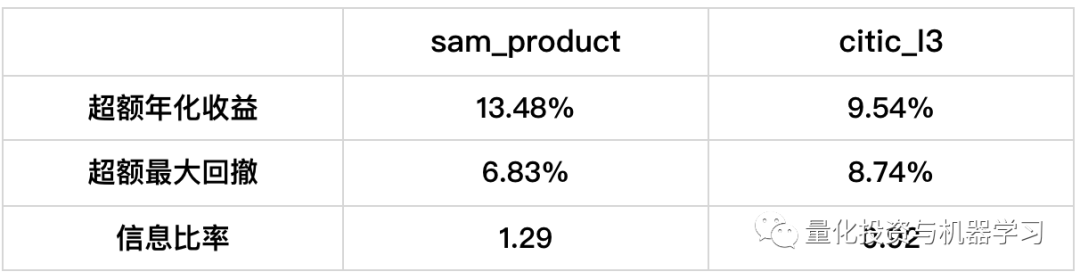
当然,我们也可以选用更多更有效的预定义概念,比如下面这篇量化投资与机器学习公众号的文章就使用数库SAM产业链数据中的产品节点作为预定义概念,在2020.12-2022.02的回测时间中获得了13.48的超额收益。
Hidden concept module
这里,我们假设隐含概念的数量与股票数量一致,都为$n$。并假设概念$i$的表征$u_i^{t,0}$为对应股票$i$的表征 $x_i^{t,1}$
使用余弦距离计算股票$i$与概念$k$之间的相似性:
$$
\gamma_{k,i}^t=Cosine(x_i^{t,1}, u_i^{t,0})
$$
将股票与相似度最高的概念进行连接(除了原先对应的概念,如股票1与概念1),如下图所示:股票1与概念2连接,而概念3没有股票与其连接,则把概念3删掉。然后再把每个股票原先对应的概念加回来,如下图(b)所示。
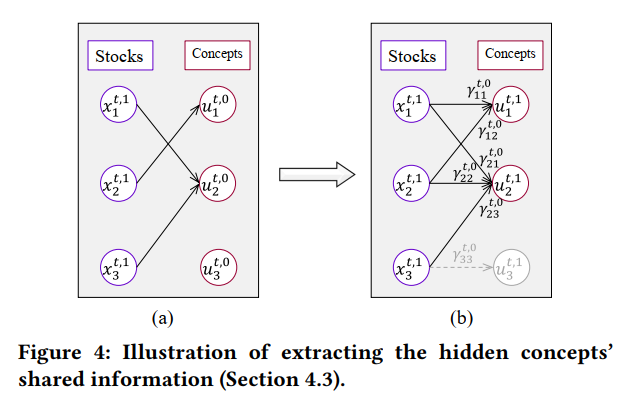
随后通过一个全连接层计算隐含概念的表征:
$$
u_k^{t,1}=LeakyRelLU(W_u(\sum_{i \in N_k^t}\gamma_{k,i}^tx_i^{t,1})+b_u)
$$
后续计算股票在隐含概念相关的共同信息的步骤和Predefined Concept Module中的步骤一致,得到$\hat x_i^{t,1},\hat y_i^{t,1}$。计算得到$x_i^{t,2}=x_i^{t,1}-\hat x_i^{t,1}$作为下一个模块的输入;$\hat y_i^{t,1}$就是本模块的最终结果,代表着最终的获得的“隐含信息”。
Individual information module
经过以上两个模型的信息剥离,每个股票都只包含里自身的特质信息,这些信息再经过一个全连接层输入为最后预测股票收益的信息:
$$
\hat y_i^{t,2} = LeakyReLU(W_{f2}\hat x_i^{t,2}+b_{f2})
$$
All Module
以上三个Moudle的输出最终放到一个线性全连接层:
$$
p_i^t=W_py_i^t+b_p=W_p(\hat y_i^{t,0}+\hat y_i^{t,1}+\hat y_i^{t,2})+b_p
$$
训练的损失函数为:
$$
L=\sum_{t\in T}MSE(p^t,d^t)=\sum_{t\in T}\sum_{i \in S^t}\frac{(p^t-d^t)^2}{|S^t|} \
$$
原文结论
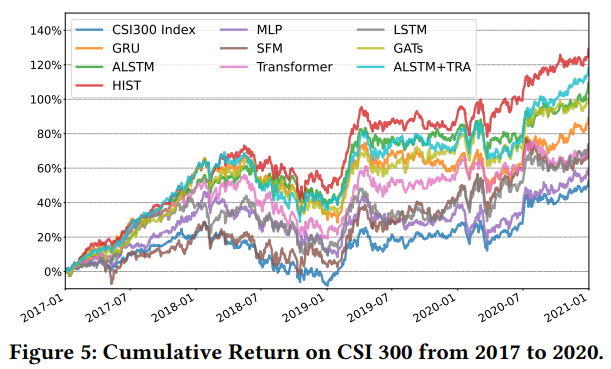
在所有的模型中,不论是在CSI100中选股还是在CSI300中进行建模,HIST模型的IC和RankIC都是最高的。比如在CSI300的测试中,RankIC达到了12.6%。
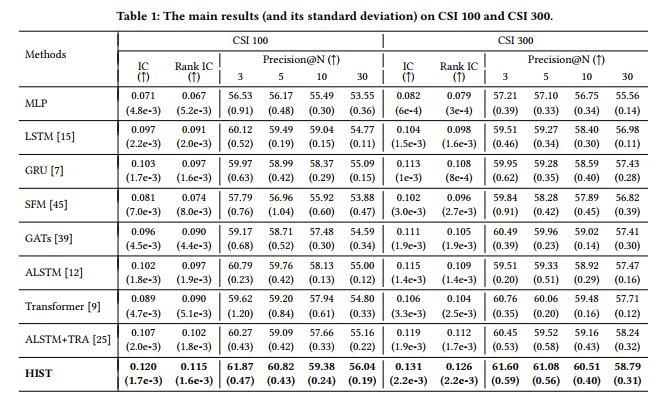
在考虑交易成本(买入万五,卖出万分之十五)的日度交易策略中,每日买入收益预测最高的前30只股票,在2017年到2020年,模型的累计收益为50%,是所有测试模型中收益最高的。