【编程学习】在Python中有效使用Parquet数据格式

【编程学习】在Python中有效使用Parquet数据格式
6Young基础使用
首先我们先构建一个虚拟的数据框来用于测试:
1 | from faker import Faker |
最简单的使用方法,就是像csv文件格式一样,直接用pandas读写即可:
1 | # 将数据保存为parquet |
文件分块保存与读取
我们可以根据自己的需求,在保存数据时按照某个指标的值进行分类保存,具体的可以看代码:
1 | df.to_parquet("test_data_partition", partition_cols="age") |
这样,我们就可以看到在test_data_partition路径下有众多age=18类似的文件,里面就是原数据中所有age=18的数据。
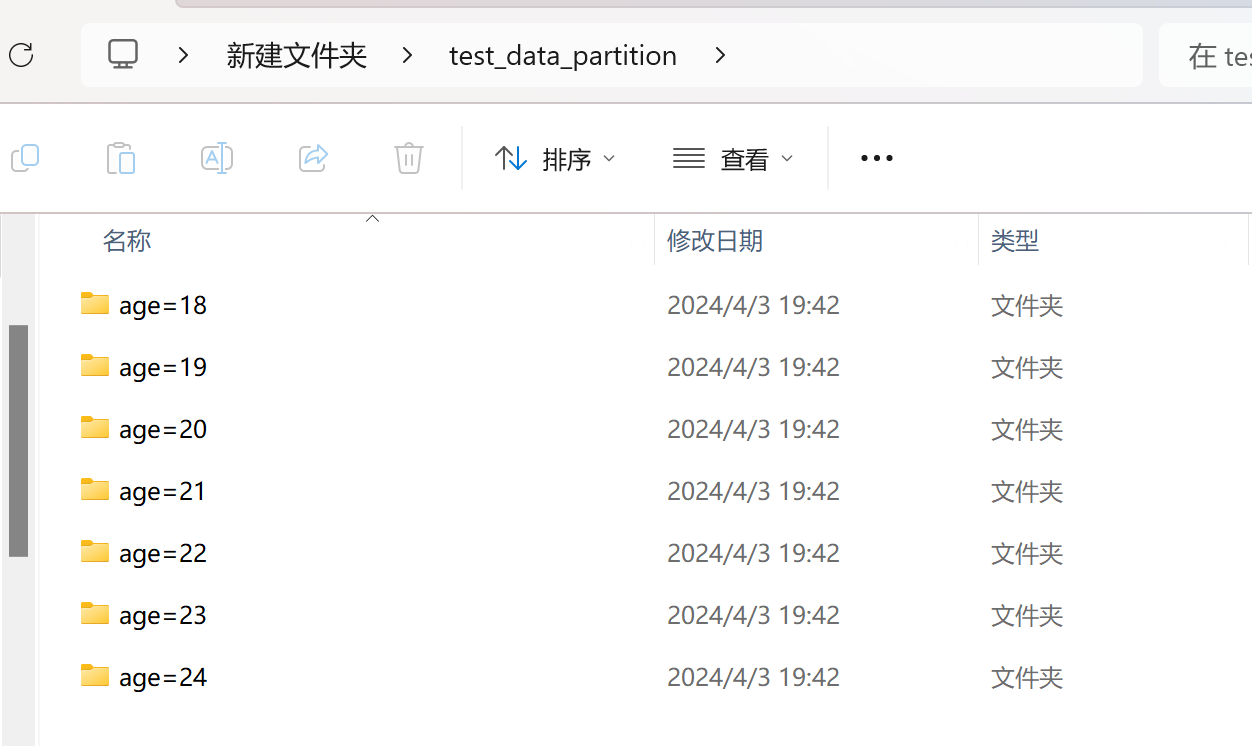
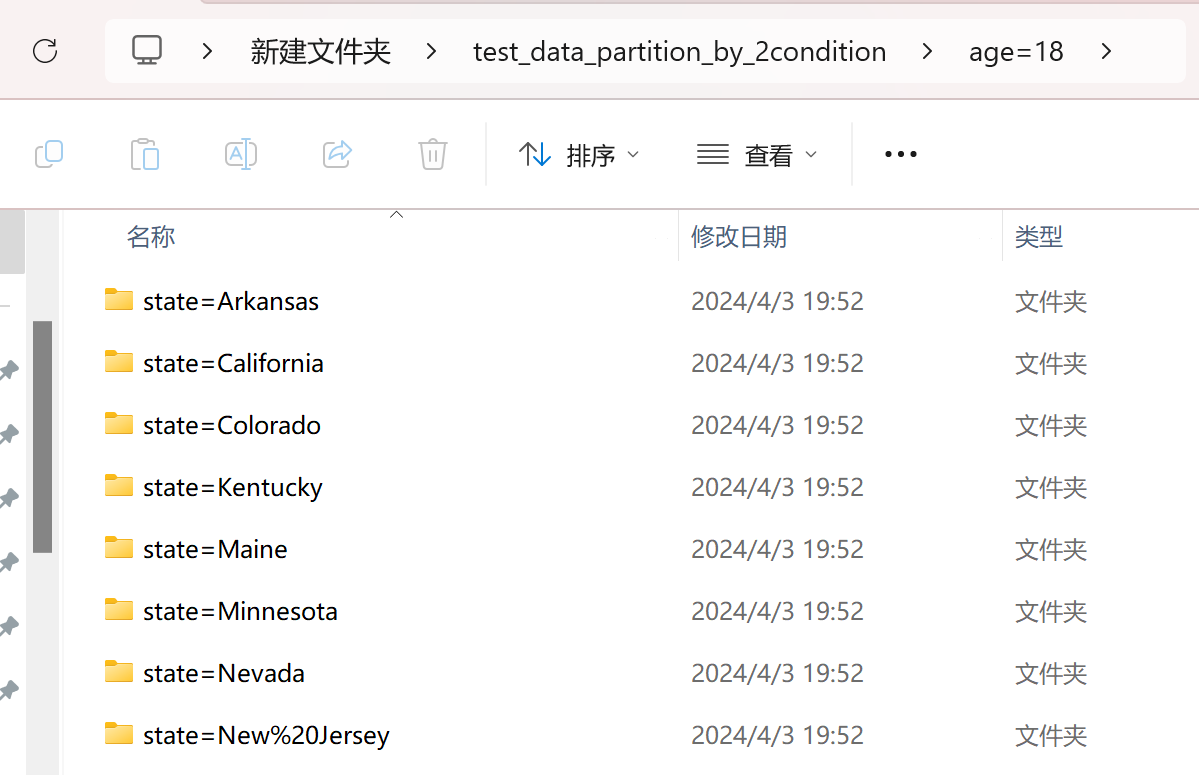
当然,用于分割的字段并不唯一,你可以同时对多个字段进行切分,这样的话,在保存路径中就会有多级嵌套的文件夹:
1 | df.to_parquet("test_data_partition_by_2condition", partition_cols=["age", 'state']) |
想要读取数据,你就直接读取保存时的路径即可:
1 | df2 = pd.read_parquet("test_data_partition") |
此外,你还可以读取里面分割出的子文件,比如,只想读取age=18的数据,那么就可以直接这样写,但是要注意,这样读取的结果中,就不存在age列了:
1 | df3 = pd.read_parquet("test_data_partition/age=18/") |
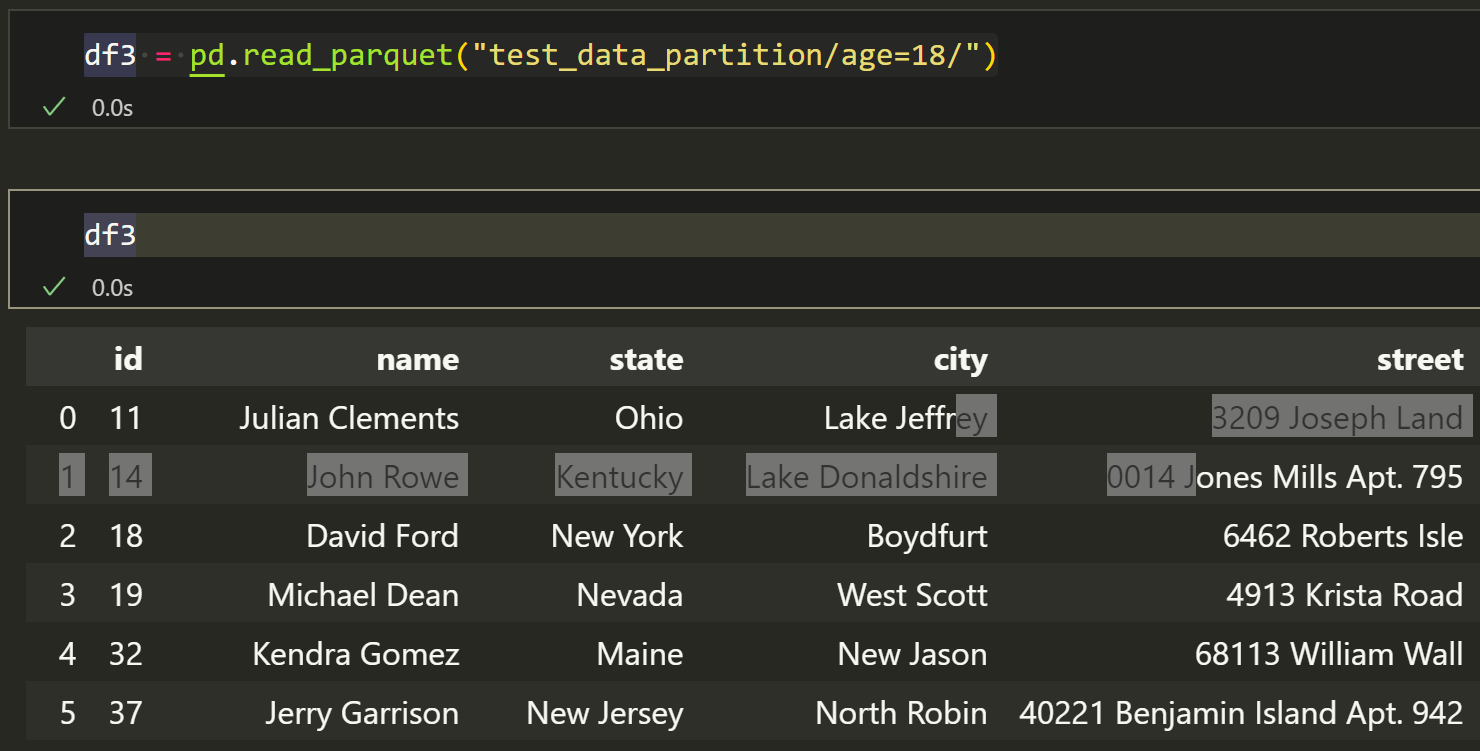
这样保存的好处其实在于,当你只想获得age=18的数据时,你就可以直接用上面的方法有条件的读取数据,这样的筛选方法比常规读入DataFrame后再筛选效率高很多。
数据的条件读取
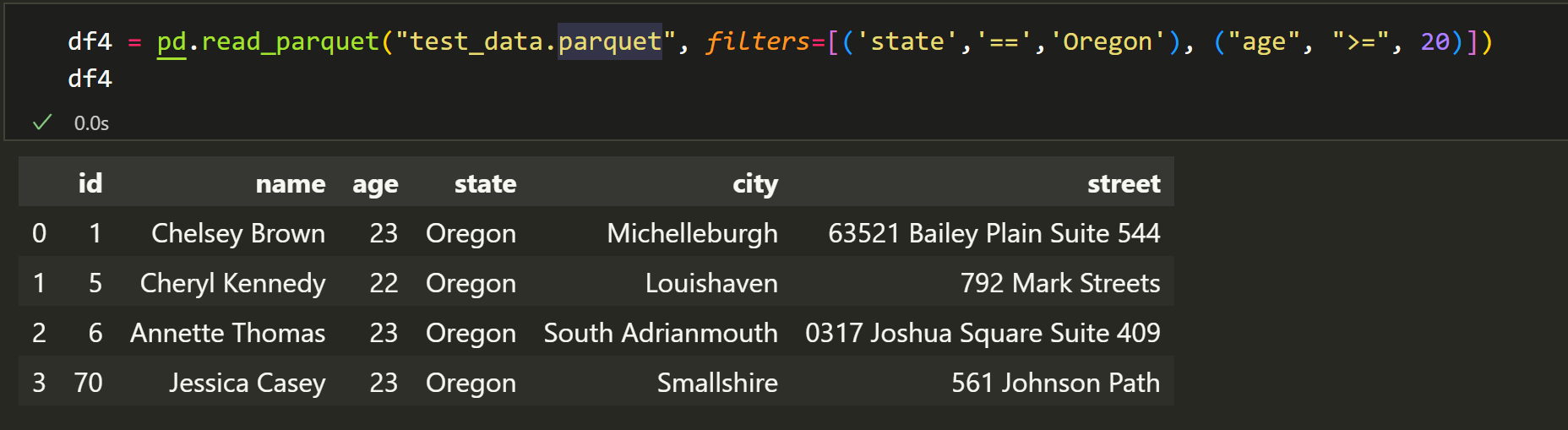
如果想要将数据按条件进行一些筛选,但是你并没有像上一板块一样将数据分类保存。常规的操作也就只是读取DataFrame后再筛选,但是parquet文件格式给了我们更多的选择:
1 | df3 = pd.read_parquet("test_data.parquet", filters=[('state','==','Oregon'), ("age", ">=", 20)]) |
这样,我们就可以直接读取符合我们需求的数据了。
而且,如果只想读取某些列,parquet也可以很方便的实现,可以通过columns参数直接选择需要的字段,大大避免了读入全部数据再处理带来的巨大内存消耗。
1 | df4 = pd.read_parquet(path="test_data.parquet", columns=["name", "state"]) |


喜欢这篇文章的人也看了





评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果






