【编程学习】大数据平台基础课程要点总结——Spark基础

【编程学习】大数据平台基础课程要点总结——Spark基础
6Young在此附上老师教学课件地址:
Spark
Spark&Hadoop
Spark是集群计算技术,专为快速计算而设计。它以Hadoop MapReduce为基础,并进一步扩展了MapReduce模型,可有效地用于更多类型的计算,包括交互式查询和流处理等。Spark的主要特点是它可以进行内存集群计算,可以提高应用程序的处理速度。Spark还在内存中加载数据,使操作速度远远快于Hadoop的磁盘存储。Spark利用最先进的DAG调度器、查询优化器和物理执行引擎,实现了批处理数据和流数据的高性能。最早的一项研究结果表明,通过使用内存数据集,运行逻辑回归使 Spark 的运行速度比Hadoop快10倍。还有研究结果表明,使用Hadoop排序100TB数据需要72分钟和2100台计算机,而使用Spark只需要23分钟和206台计算机。
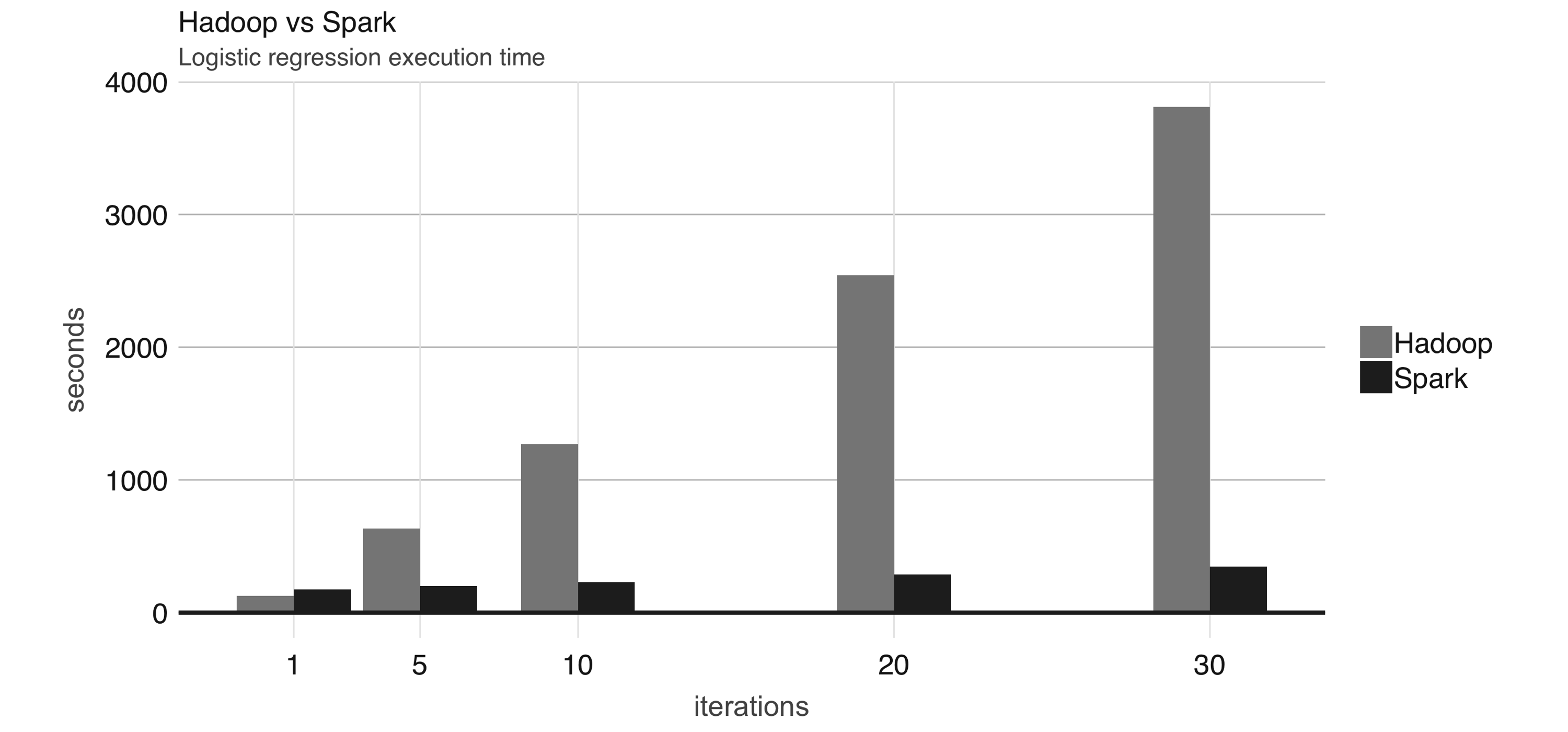
除此以外,Spark提供Java、Scala、Python、R 和SQL的API,让我们以更熟悉的方法运用这一框架。
Spark 比Hadoop更容易使用;例如,单词计数MapReduce示例在Hadoop中需要大约 50 行代码,而在 Spark 中只需要 2 行代码。
Spark 还支持丰富的高级工具集,包括用于SQL和结构化数据处理的Spark SQL、用于 pandas工作的Spark上的pandas API、用于机器学习的MLlib、用于图形处理的GraphX以及用于增量计算和流处理的Structured Streaming。
可以看出,Spark 比 Hadoop 更快、更高效、更易用。
特征
灵活:Spark允许使用喜欢的语言,统一处理批量数据和实时数据流,比如Python、SQL、Scala、Java或R等;
SQL 分析: Spark允许执行快速、分布式ANSI SQL查询,用于仪表盘和临时报告。运行速度比大多数数据仓库还快。
大数据: 允许在PB级数据上执行探索性数据分析,而无需采用降采样。
机器学习: 允许在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到由数千台机器组成的容错集群。
LIBRARIES OF SPARK
SQL 和 DataFrames 是一个用于处理结构化数据的模块。Spark SQL 允许我们在 Spark 程序中查询结构化数据。DataFrames 和 SQL 提供了访问各种数据源的通用方法,包括 Hive、Avro、Parquet、ORC、JSON 和 JDBC。Spark Streaming 利用 Spark Core 的快速调度能力来执行流式分析。它以迷你批次提取数据,并对这些迷你批次数据执行 RDD(弹性分布式数据集)转换。MLlib 符合 Spark 的 API,并可与 Python 中的 NumPy(截至 Spark 0.9)和 R 库(截至 Spark 1.5)互操作。在这个过程中,我们可以使用任何 Hadoop 数据源(如 HDFS、HBase 或本地文件),从而轻松插入 Hadoop 工作流。MLlib 包含多种算法和实用程序:分类、聚类、推荐、文本挖掘等。GraphX 一个基于 Spark 的分布式图形处理框架。它提供了一个表达图计算的 API,可通过使用 Pregel 抽象 API 对用户定义的图进行建模。它还为这种抽象提供了优化的运行时。
SPARK RDD
弹性分布式数据集(RDD)是 Spark 的一种基本数据结构。是一个不可变的分布式对象集合。RDD 中的每个数据集都被划分为逻辑分区,可在集群的不同节点上进行计算。RDD 可以包含任何类型的 Python、Java 或 Scala 对象,包括用户定义的类。
创建 RDD 有两种方法:并行化驱动程序中的现有集合,或引用外部存储系统中的数据集,如共享文件系统、HDFS、HBase 或任何提供 Hadoop 输入格式的数据源。
RDD&Hadoop
MapReduce 计算模型采用 HDFS 作为算子(Map 或 Reduce)之间的数据接口,所有算子的临时计算结果都以文件的形式存储到 HDFS 以供下游算子消费。下游算子从 HDFS 读取文件并将其转化为键值对(江湖人称 KV),用 Map 或 Reduce 封装的计算逻辑处理后,再次以文件的形式存储到 HDFS。
在不断读写文件的过程中,磁盘IO就产生了大量的时间消耗,使得任务的完成变慢。所以我们希望在这个过程中减少读写操作,这也就是RDD诞生的背景。
为了弄清楚 RDD 的基本构成和特性,我们从它的 5 大核心属性说起。
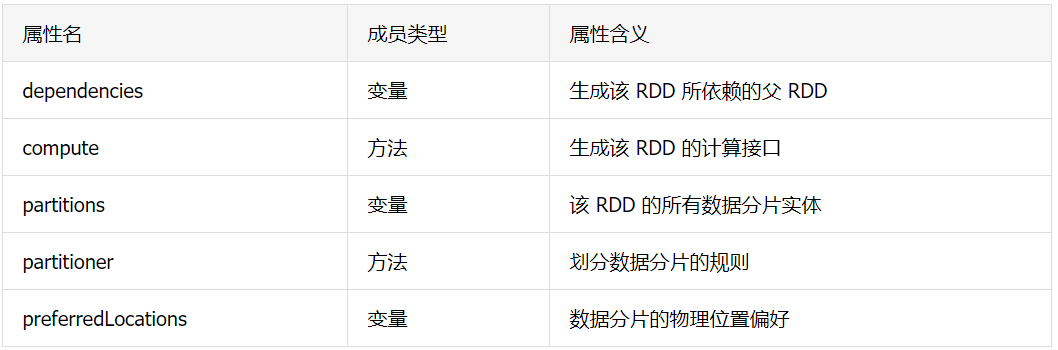
对于 RDD 数据模型的抽象,我们只需关注前两个属性,即 dependencies 和 compute。任何一个 RDD 都不是凭空产生的,每个 RDD 都是基于一定的“计算规则”从某个“数据源”转换而来。dependencies 指定了生成该 RDD 所需的“数据源”,术语叫作依赖或父 RDD;compute 描述了从父 RDD 经过怎样的“计算规则”得到当前的 RDD。这两个属性看似简单,实则大有智慧。
与 MapReduce 以算子(Map 和 Reduce)为第一视角、以外部数据为衔接的设计方式不同,Spark Core 中 RDD 的设计以数据作为第一视角,不再强调算子的重要性,算子仅仅是 RDD 数据转换的一种计算规则,map 算子和 reduce 算子纷纷被弱化、稀释在 Spark 提供的茫茫算子集合之中。dependencies 与 compute 两个核心属性实际上抽象出了“从哪个数据源经过怎样的计算规则和转换,从而得到当前的数据集”。父与子的关系是相对的,将思维延伸,如果当前 RDD 还有子 RDD,那么从当前 RDD 的视角看过去,子 RDD 的 dependencies 与 compute 则描述了“从当前 RDD 出发,再经过怎样的计算规则与转换,可以获得新的数据集”。
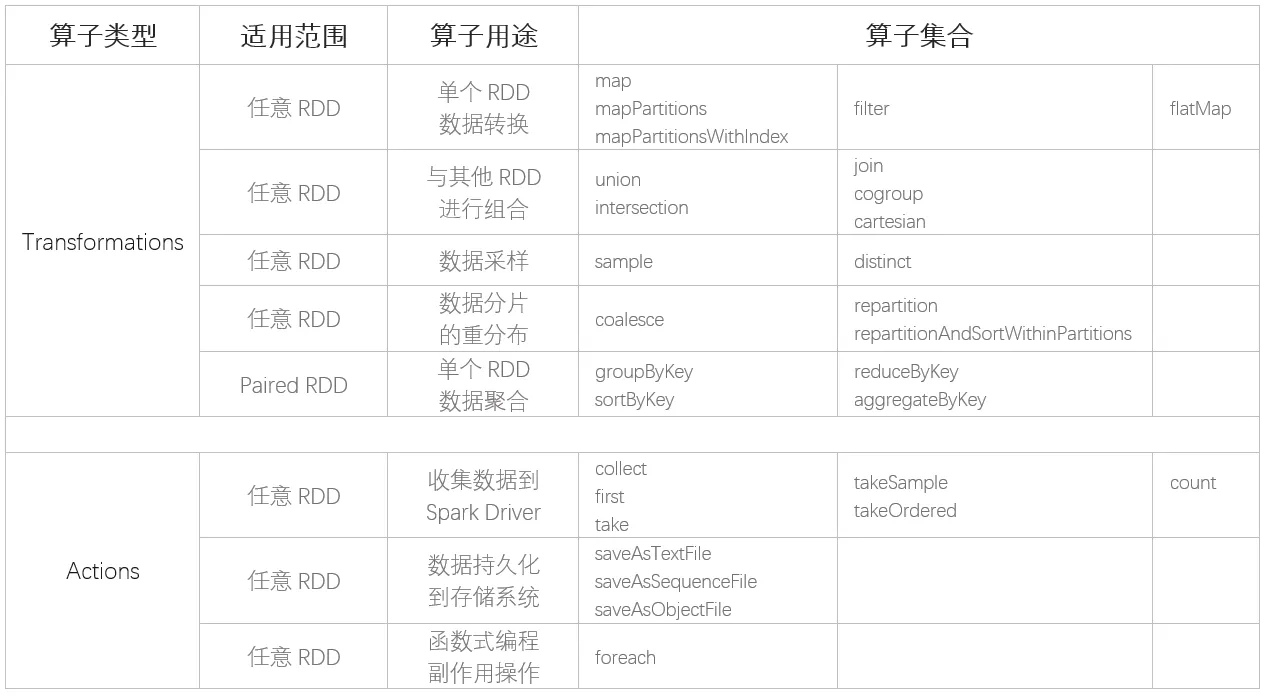
所以总结spark比mapreduce快的原因有以下几点:
DAG相比hadoop的mapreduce在大多数情况下可以减少磁盘I/O次数
因为mapreduce计算模型只能包含一个map和一个reduce,所以reduce完后必须进行落盘,而DAG可以连续shuffle的,也就是说一个DAG可以完成好几个
mapreduce,所以dag只需要在最后一个shuffle落盘,就比mapreduce少了,总shuffle次数越多,减少的落盘次数就越多
spark shuffle 的优化
mapreduce在shuffle时默认进行排序,spark在shuffle时则只有部分场景才需要排序(bypass技师不需要排序),排序是非常耗时的,这样就可以加快shuffle速度
spark支持将需要反复用到的数据进行缓存
所以对于下次再次使用此rdd时,不再再次计算,而是直接从缓存中获取,因此可以减少数据加载耗时,所以更适合需要迭代计算的机器学习算法
任务级别并行度上的不同
mapreduce采用多进程模型,而spark采用了多线程模型,多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间,即mapreduce的map task 和reduce task是进程级别的,都是jvm进程,每次启动都需要重新申请资源,消耗不必要的时间,而spark task是基于线程模型的,通过复用线程池中的线程来减少启动,关闭task所需要的开销(多线程模型也有缺点,由于同节点上所有任务运行在一个进行中,因此,会出现严重的资源争用,难以细粒度控制每个任务占用资源)
Spark的使用
Spark batch:
spark-submit <SparkApp.py>spark-submit \ --class <main-class> \ --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- SparkR: `sparkR` 已经被移除了,可以在这里继续使用R版本的Spark[`sparklyr`](https://spark.rstudio.com/).
- PySpark: `pyspark`
- Spark-shell: `spark-shell`
- 在Yarn集群上运行Python应用程序
- ```bash
PYSPARK_PYTHON=python3.9 spark-submit \
--master yarn \
--executor-memory 20G \
--num-executors 50 \
examples/src/main/python/pi.py \
1000
通过PySpark-shell运行Spark
PYSPARK_PYTHON=python3.9 pyspark1
2
3
4
5
6
7
8
- 在Python中运行Spark
- ```python
import findspark
findspark.init('/usr/lib/spark-current/')
# Then you could import the `pyspark` module
import pyspark
Spark数据类型
不同点
RDD(2011, spark 1.0)RDD一般和spark mllib同时使用RDD不支持Spark SQL操作# SparkSession创建RDD from pyspark.sql.session import SparkSession spark = SparkSession.builder.master("local") \ .appName("My test") \ .getOrCreate() sc = spark.sparkContext data = [1, 2, 3, 4, 5, 6, 7, 8, 9] rdd = sc.parallelize(data)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
- DataFrames (2013, spark 1.3)
- `DataFrame`每一行的类型固定为Row, 每一列的值没法直接访问,只有通过解析才能获取各个字段的值。
- `DataFrame`一般不与`spark mllib`同时使用。
- `DataFrame`支持`Spark SQL`的操作,比如select,groupby 之类,还能注册临时表/视窗,进行sql语句操作。
- ```python
# 直接创建DataFrame
df = spark.createDataFrame([
(1, 144.5, 5.9, 33, 'M'),
(2, 167.2, 5.4, 45, 'M'),
(3, 124.1, 5.2, 23, 'F'),
], ['id', 'weight', 'height', 'age', 'gender'])
# 从字典创建DataFrame
df = spark.createDataFrame([{'name':'Alice','age':1}, {'name':'Polo','age':1}])
# 指定schema创建DataFrame
schema = StructType([
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("age", LongType(), True),
StructField("eyeColor", StringType(), True)
])
df = spark.createDataFrame(csvRDD, schema)
# 读文件创建DataFrame
df = spark.read.csv(FilePath, header='true', inferSchema='true', sep='\t')
# 从pandas dataframe创建DataFrame
colors = ['white','green','yellow','red','brown','pink']
color_df=pd.DataFrame(colors,columns=['color'])
color_df['length']=color_df['color'].apply(len)
color_df=spark.createDataFrame(color_df)
color_df.show()
# 从hive中读取数据
from pyspark.sql import SparkSession
myspark = SparkSession.builder \
.appName('compute_customer_age') \
.config('spark.executor.memory','2g') \
.enableHiveSupport() \
.getOrCreate()
sql = """
SELECT id as customer_id,name, register_date
FROM [db_name].[hive_table_name]
limit 100
"""
df = myspark.sql(sql)
# 数据保存
DataFrame.write.mode("overwrite").saveAsTable("test_db.test_table2")# 查看有哪些列 ,同pandas df.columns # 行数 df.count() # 列数 len(df.columns) # 统计频繁项目(查找每列出现次数占总的30%以上频繁项目) df.stat.freqItems(["id", "gender"], 0.3).show() # 多列选择和切片 color_df.select('length','color') .select(color_df['length']>4).show() # between 范围选择 & 多重筛选 color_df.filter(color_df.length.between(4,5)) .filter(color_df[0]!='white') .select(color_df.color.alias('mid_length')).show() # filter运行类SQL color_df.filter("color='green'").show() color_df.filter("color like 'b%'").show() # where方法的SQL color_df.where("color like '%yellow%'").show() # 直接使用SQL语法 # 聚合函数 from pyspark.sql import functions as F df_res.agg( F.count('member_name').alias('mem_num'), F.sum('num').alias('order_num'), F.sum("income").alias('total_income') ).show() # 修改列数据类型 from pyspark.sql.types import IntegerType df = df.withColumn("height", df["height"].cast(IntegerType())) df = df.withColumn("weight", df.weight.cast('int')) # 排序 color_df.sort(color_df.length.desc(),color_df.color.asc()).show() color_df.orderBy('length','color').show()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- Datasets (2015, spark 1.6)
- `DataSet`一般不与`spark mllib`同时使用。
- `DataSet`支持`Spark SQL`的操作,比如select,groupby 之类,还能注册临时表/视窗,进行sql语句操作。
- `DataSet`和`DataFrame`拥有完全相同的成员函数,区别只是每一行的数据类型不同。**DataFrame其实就是DataSet的一个特例。**
- DataFrame也可以叫DataSet[Row],每一行类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面的getAs方法或者共性中的第七条提到的模式匹配拿出特定字段,而DataSet中,每一行是什么类型是不一定的,在自定义case class之后可以很自由的获取每一行的信息。
#### 共同点
1. `RDD`、`DataFrame`、`DataSet`全都是`spark`平台下的分布式弹性数据集,为处理超大型数据提供便利;
2. 三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算;
3. 三者有许多共同的函数,如filter, 排序等;
4. 三者都会根据Spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出。
5. 三者都有partition的概念
6. `DataFrame`和`DataSet`均可使用模式匹配获取各个字段的值和类型
#### 互相转化(PySpark中一般使用RDD和DataFrame即可)
```python
# RDD转变成DataFrame
df.toDF(['col1','col2'])
# DataFrame转变成RDD
df.rdd.map(lambda x: (x.001,x.002))
# DataFrame转pd.DataFrame
df.toPandas()
案例实操
1 | # Load a text file and convert each line to a Row. |
注意,此处我们使用file:///home/data/data.csv或/home/data/data.csv代表本地路径,spark会在服务器上寻找对应文件,hdfs://<HDFS_SERVER>:<HDFS_PORT>/path/to/hdfs/file代表spark会去HDFS中寻找对应的数据













