【编程学习】用numpy求解线性回归并使用numba加速

【编程学习】用numpy求解线性回归并使用numba加速
6Young在平时使用python进行线性回归时,我们通常使用的都是sklearn库或statsmodel库,这固然是被各路大神优化过无数次的代码了。但是如果在计算线性回归的过程中嵌套很多其他的步骤,可能就会较为耗时,这两个库的优化效果是没有办法提升其他部分的效率的。而numba库可以有效地提高numpy库中的大部分函数与绝大部分的python原生函数,而且使用方法简单,只需要添加一行代码,是极佳的提升效率的方案,使用numba就可以实现对多次线性回归的高效计算了。那就让我们依次进行吧~
使用numpy线性回归
对于多元线性回归模型:
$$
y = \beta_0 + x_1\beta_1 + x_2\beta_2 + … + x_n\beta_n
$$
我们有m个样本用以计算回归模型,并由此构建出m个方程:
$$
\begin{align}
\nonumber
y_1 &= \beta_0 + x_{11}\beta_1 + x_{12}\beta_2 + … + x_{1n}\beta_n + \alpha\\
\nonumber
y_2 &= \beta_0 + x_{21}\beta_1 + x_{22}\beta_2 + … + x_{2n}\beta_n + \alpha\\
\nonumber
… \\
\nonumber
y_m &= \beta_0 + x_{m1}\beta_1 + x_{m2}\beta_2 + … + x_{mn}\beta_n + \alpha
\end{align}
$$
写成矩阵形式就是(其中X中包含一列1):
$$
y = X\beta
$$
如此可以直接得到$\beta$的表达式
$$
\beta = (X^TX)^{-1}X^Ty
$$
如此可以简单地通过python来实现了:
1 | beta = np.dot(np.dot(np.linalg.inv(np.dot(X.T,x)),X.T), y) |
各种方法效率对比
预先准备环境:
1 | from numba import njit |
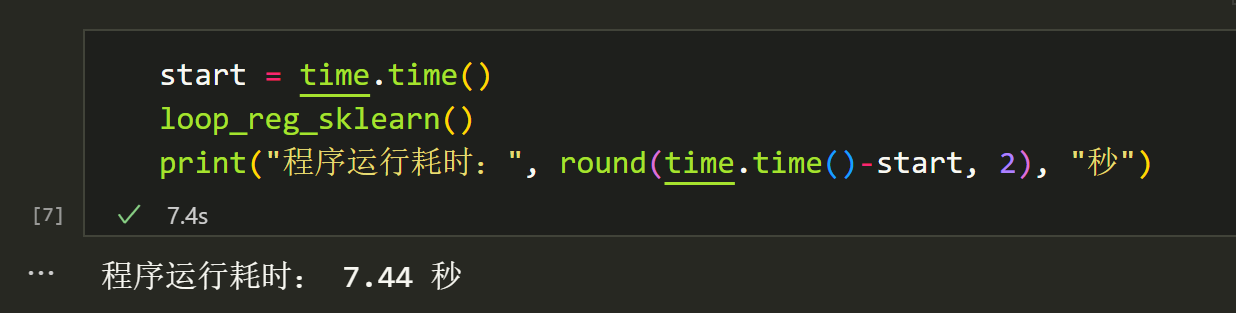
先来一个函数,他是使用skLearn库的LinearRegression实现的:
1 | def loop_reg_sklearn(): |
再用numpy实现一下:
1 | def loop_reg(): |
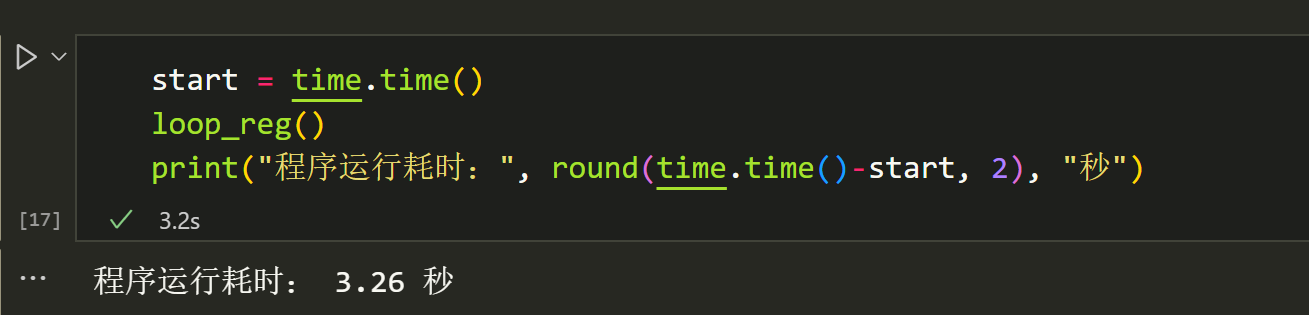
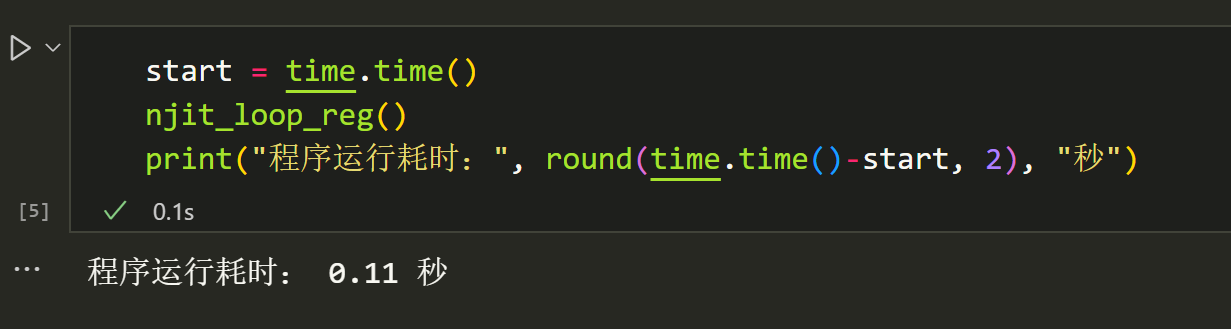
发现numpy计算就已经比sklearn快很多了,当然,里面也有我只使用numpy计算回归系数,没有计算其他数据的小部分原因,但是整体上numpy应该是快很多的。
再来看看numba的效果吧!
1 |
|
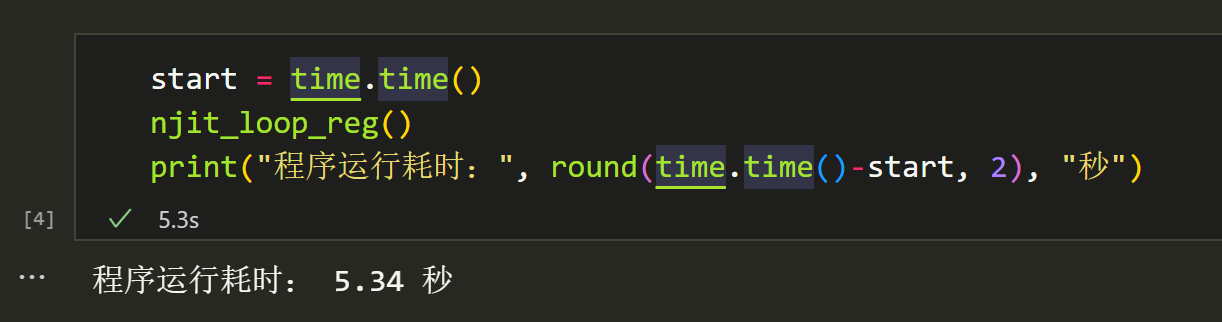
第一次运行,速度较慢,因为程序需要将代码编译为机器码,之后的运行就非常快了,有30倍以上的速度提升: